by Vahe Andonians on Dec 14, 2022 2:14:09 AM
Progress in artificial intelligence is often measured by the ability to defeat humans. We are equally fascinated and shocked by AlphaGo winning against the best Go players in the world – the last widespread game where humans dominated machines. But even before the first intelligent machines were developed, Alain Turing suggested measuring them by comparing them to humans in an imitation game.
Seventy years later, we still follow the same paradigm even though evidence of superior human-machine cooperation is piling up. In this post, I am outlining why a thoughtfully designed collaboration between humans and artificial intelligence has emerged as the most promising way of integration.
Knowledge
We can identify a dog in a picture, yet we cannot specify a clear set of rules leading to the same result.

We know much more than we can tell. Polyani argues that this "self-ignorance" is common to many human activities, from driving a car in traffic to face recognition. Humans rely on their intrinsic knowledge, which is challenging to express when engaging in these tasks.
As a result, we have been unable to automate many tasks as computers require a high degree of exactness.
The strengths and weaknesses of deep learning
With deep learning, we have created a technology that overcomes the need for exact rules by making a basic copy of the brain's nervous tissue and teaching it through examples.
This opens up massive new possibilities. It was impossible to extract tables from documents using rules. The layout of a page is inconceivable for any other method, including traditional machine learning. Robotic process automation requires constantly adapting to even slightly changing document formats.
In contrast, deep learning artificial neural networks learn the grammar of a domain. They learn things like – headers are in a certain relationship to the body text, which distances and emphasizes them. Because they learn this grammar rather than rules, they are remarkably resilient to varying input.
Just take Google image search as an example. If we search for "dog," we are presented with millions of dog images. Google correctly classifies all kinds of dogs regardless of size, zoom, aspect ratio, cropping, or pixels.
Equally, deep learning can learn the countless page layouts of documents. Or it can learn the myriad ways of expressing the number of electric cars owned by a company or its overall carbon footprint. Information that otherwise would require a fully manual process.
Deep learning can be used to save money, speed up processing time, and – given the tremendous growth rate of unstructured data – including previously unused data. According to recently published research by ITC, 80% of all data are unstructured; by 2025, 175 zettabytes of data will be unstructured. Harnessing these data converts them from a liability to a true asset and empowers us to serve our clients better.
With all these possibilities, there is, unfortunately, also a difficulty. Deep learning models need a humongous amount of training data. And even after they have been trained on petabytes of data, they sometimes struggle with apparently easy tasks.
Just recall that deep learning beats every human in Chess or Go and even poker, which all require exhausting concentration from humans to even play at a mediocre level.
Conversely, deep learning struggles with this image.

Admittedly, this is a constructed image, but we can easily see the difference between the ice cream cones and the Shar Pei.
Deep learning sees a lot of odd things like "wood," "sleeve," or "baked good," but it misses all eight Shar Pei pictures.
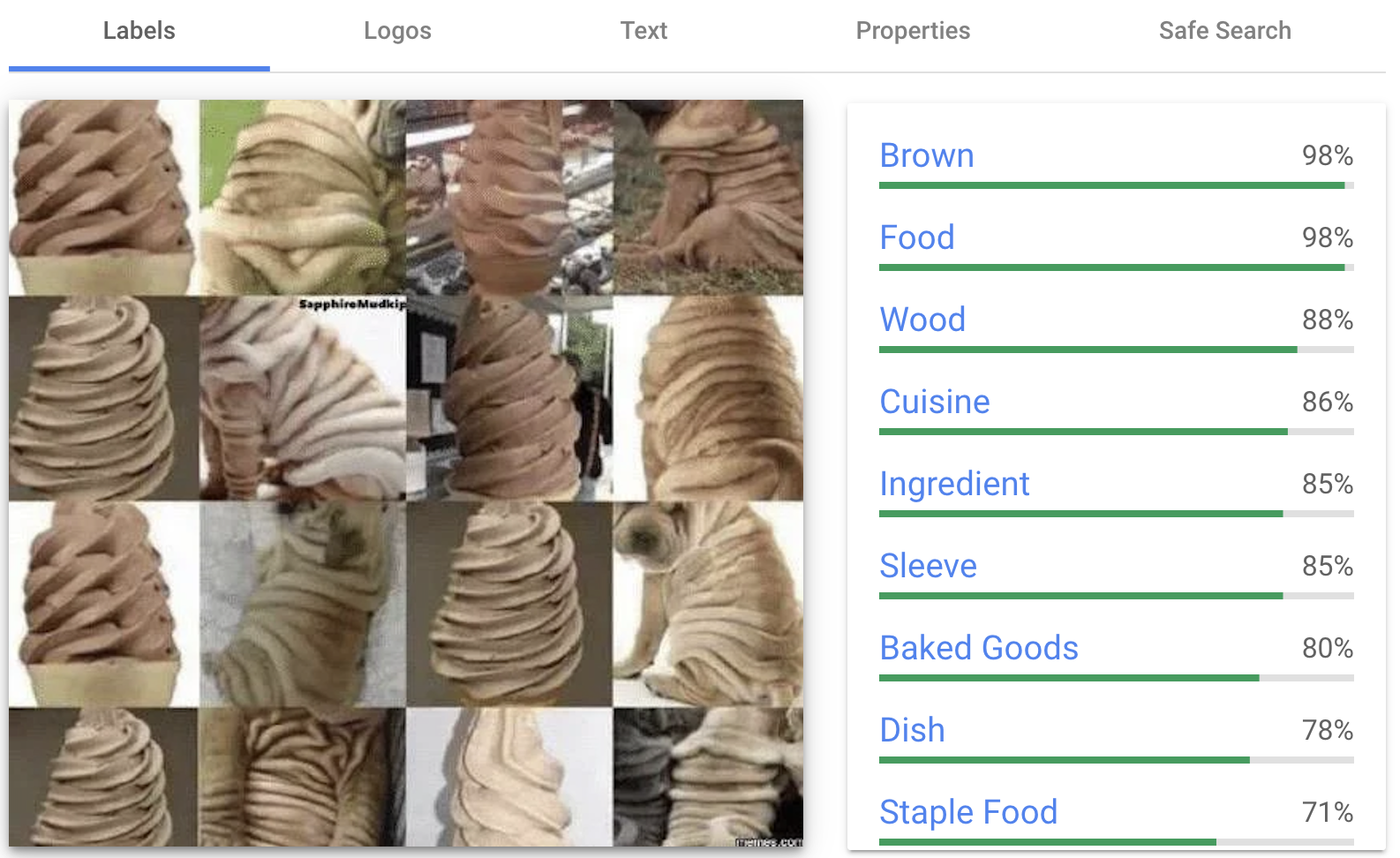
Currently, the only solution to this is more training data. There is a theory that classifying such images, or any object, is a very difficult task. However, evolution has trained us for object detection and classification for about 540 million years.
As deep learning starts from zero, it takes significant data volumes to learn these specifically well-mastered cases by humans.
Humans are incredibly efficient, but that comes at a price
In contrast, humans have been trained to be incredible learners. The human brain is much more complex than the rudimentary copy we do when we talk about deep learning. That results in vast differences between humans and machines.
We can learn with just a few examples. In some cases, even with a single sample. Further, we can discover general laws which machines cannot do. At the age of six years, you have already realized that every number has a successor. You likely could not name them, but you discovered this general law.
There are many factors resulting in these capabilities. For example, we know that you are already born with specific knowledge about the world. You had a concept of things. You even had an idea of things that move by their will, namely other humans and animals.
The most significant difference between the current state of deep learning and humans is that we have a model of everything.
In "The Adventure of Silver Blaze", inspector Gregory asks Sherlock Holmes, "Is there any other point to which you would wish to draw my attention?"
Holmes, "To the curious incident of the dog in the night-time."
Gregor, "The dog did nothing in the night-time."
Holmes, "That was the curious incident."
Sherlock Holmes reasoned that if the dog had spotted a stranger, he would have barked. Because he did not, the criminal must have been a familiar person.
While this is a beautiful story, such reasoning is done daily by all of us. It is only possible because we have a model of a dog. We inject that model into a different situation and can draw conclusions from it.
But this comes at a price. Looking at the picture below, answer which square is darker – the square labeled A or B?

Most agree that square A is darker. But I can assure you these two squares have the same shade of grey. You will readily agree when I add these two lines.
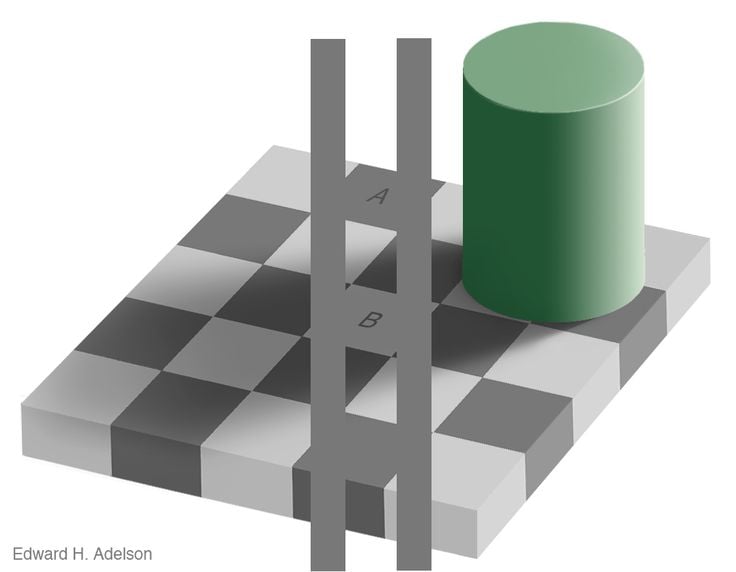
If they are the same shade, why do they look different? Even now that you know these squares have the same shade of grey, why do we still see them differently?
We see them differently because we are simply hallucinating! Rather than interpreting the retina's input and creating a model of reality, we already have models of the world and fit the data to the best model. We are using the input from the retina to see which of our existing models fits the noisy data best. In this image, there is a shadow. And our model of the world tells us that things in a shadow are lighter than they appear. Hence our brain ignores the actual data and overlies it with a model of what shadows do. As a result, we see something that is actually not there. We are hallucinating.
The process of creating a model of the world is called systematizing, and we are incredibly good at it. We learn with remarkably few data points using patterns. In fact, we are so good at it that we tend to perceive meaningful patterns and connections among unrelated events. This patternicity can even reach pathological levels, which is then called apophenia. Gamblers are good examples of apophenia. They often believe in seeing patterns in numbers that just do not exist.
Besides this bias, we have several other cognitive biases. For example, the anchoring bias has gained visibility through Daniel Kahneman's experiment. He asked a group of judges with over 15 years of experience to examine a case where a woman had been caught shoplifting multiple times. The judges were asked to roll a pair of dice between reviewing the case and suggesting a possible sentence. Unknown to the judges, the dice were rigged and would give a total of three or nine. Astonishingly, the number rolled anchored the judges when making their sentencing recommendations. Those who rolled three sentenced the woman to an average of five months in prison. Whereas those who threw a nine sentenced her to nine months.
If judges with 15 years of experience can be influenced so easily by an arbitrary anchor, then what hope do the rest of us have?
There are many more well-known cognitive biases, such as the framing bias.
Human-machine cooperation achieves superior results
Humans and deep learning have distinct strengths and weaknesses.
In contrast to deep learning models, we can differentiate between correlation and causation; and while we are superior learners, we also have biases that are difficult to control. After all, we are making about 35,000 decisions per day.
On the other hand, deep learning models are only biased through the input data, which is beneficial as it holds up a mirror of society and allows us to fix unrecognized problems. They also bring the cost of prediction down and scale almost indefinitely. However, deep learning models need significant volumes of training data to learn.
An intelligent combination in the form of Human-in-the-Loop AI creates an ideal symbiosis of human experts and AI models, harnessing the advantages of both while at the same time overcoming their respective limitations. Applied to unstructured data, it enables us to use vastly more information in our decision processes at higher speed and lower cost.
We are at an inflection point, experiencing an explosion of unstructured data – 175 zettabytes by 2025.
As Eric Schmidt, former CEO of Google, famously stated in 2010, “There were 5 exabytes of information created between the dawn of civilization through 2003….” This is 0.5% of a zettabyte. “...but that much information is now created every two days.” And the pace is continuously growing.